进程和线程管理
进程和线程管理
进程和线程的区别
- 进程是程序关于某数据集合上的一次运行活动,它包含了程序代码、数据、资源等等,是操作系统进行资源分配的最小单元;线程是进程中的一个执行单元,一个进程可以包括多个线程,CPU进行运算、调度的最小单元。
- 每个进程有自己独立的地址空间,一个进程中的线程会共享进程的内存和资源,所以进程的创建、销毁和切换的开销都远大于线程。
- 进程间通信比较复杂,需要借助操作系统提供的机制,如管道、消息队列等。线程,因为它们共享地址空间,可以使用共享变量,我们更需要关心的是线程的同步,保证线程安全。
什么是同步和互斥
同步指的是进程间的执行需要按照某种先后顺序,即访问是有序的。互斥指的是同一时刻,对于某些共享资源的访问不能同时进行。这两种情况基本构成了我们在多线程执行中遇到的各种问题。
进程之间的通信方式
【InterProcees Communication】 IPC
- 管道(pipe)
管道是一种半双工的通信方式,数据只能单向流动,只能在具有亲缘关系的进程间使用。
(管道就是一个存在于内存中的文件。是一个环形的数据结构,为了可以循环利用。在linux系统中,管道借助文件系统中的File结构实现。父进程使用FIle结构写入数据的例程地址,子进程保存从管道读出数据的例程地址。
管道是由内核管理的一个缓冲区,设计的是一个环形的数据结构,为了可以循环利用。【存在内存中】)
- 命名管道(namedpipe)
命名管道也是半双工的通信方式,和管道其他都类似。允许本机任意两个进程通信。
- 消息队列(messagequeue)
消息队列允许一个进程向另一个进程发送消息,消息在队列中按顺序存储,并且接收方可以按需接收。
(消息队列是消息的链表,存放在内核中,每个消息都是一个数据块,具有特定的格式。允许一个或多个进程向他写入或读取消息,消息的发送者和接收者不需要同时与消息队列进行交互,消息会保存在队列中,也就是说,消息队列是异步的。接收者必须轮询消息队列,才能收到最近的消息。【存在内核中,只有在内核重启或者操作系统显式删除消息队列时,消息队列才会被删除】)
消息队列和管道的区别:
- 消息队列中的数据是有格式的
- 取消息进程可以选择接收特定类型的消息,而不是像管道中那样默认全部接收。
- 共享内存(shared memory)
共享内存允许多个进程访问同一块内存区域,从而实现快速的数据交换。但需要注意同步问题。
- 信号量机制(semophore)
信号量用来控制多个进程对共享资源的访问,可以用于实现进程间的互斥访问、同步操作。
(对它的操作都是原子的,有两种操作(P(wait()操作,会减少信号量的值);V(signal()操作,会增加信号量的值)))。如果信号量只有0或1,二进制信号量,可以作为互斥锁,实现进程间的互斥。)
- 套接字(socket)
可用于网络上不同主机上的进程通信。(需要通信的进程之间首先要各自创建一个socket,IP地址:端口号。进程通过socket把消息发送到网络层中,网络层通过主机地址把消息发到目的主机,目的主机通过端口号发给对应进程。)
哪种进程间通信方式最快?
共享内存最快,因为数据之间映射到进程的地址空间,不需要内核的参与。但是需要额外的同步控制来保证线程安全。
线程之间的通信/同步方式
由于线程之间是共享地址空间的,所以它们之间的通信不用调用内核。【为什么进程之间的通信必须借助内核,因为每个进程都有自己的独立地址空间,在操作系统和硬件的地址保护机制下,进程是无法访问其他进程的地址空间的,所以必须借助操作系统的系统调用函数进行通信。】而是要做好同步/互斥,保护共享的全局变量。
- 锁机制
- 互斥锁,以排他的方式防止数据被并发修改
- 读写锁,允许多个线程同时读共享数据,对写操作是互斥的
- 信号量机制【就和刚刚介绍的进程信号量机制是类似的】0-1信号量和互斥锁的区别:首先信号量机制是用于同步的,并没有锁定资源;互斥锁就是用于互斥的,对互斥数据进行锁定。0-1信号量完全可以代替互斥锁,但是由于互斥锁较为简单,并且效率高,所以必须要保证资源互斥的情况下,还是使用mutex。
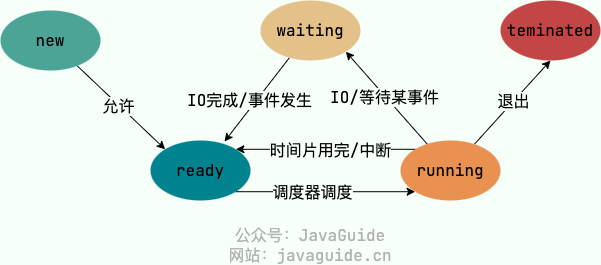
进程有哪几种状态?
- 创建状态(new):进程正在被创建,尚未到就绪状态。
- 就绪状态(ready):进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
- 运行状态(running):进程正在处理器上运行
- 阻塞状态(waiting):进程正在等待某一事件而暂停运行,比如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
- 结束状态(terminated):进程正常结束或其他原因中断退出运行。
进程(线程)的调度算法有哪些
tip:进程调度指操作系统按照某种策略选择进程占用CPU进行运行
- 先到先服务调度算法(FCFS,First Come, First Served) : 从就绪队列中选择一个最先进入该队列的进程为之分配资源,并且是非抢占调度算法
- 短作业优先的调度算法(SJF,Shortest Job First) : 从就绪队列中选出一个估计运行时间最短的进程为之分配CPU资源。
- 高响应比优先调度算法,先计算响应比优先级=(等待时间+要求服务时间)/要求服务时间。如果两个进程等待时间相同,要求服务时间越短,响应比越高,短作业进程容易被选中;两个进程要求服务时间相同,等待时间越长,响应比越高,兼顾了长作业进程,避免长作业饥饿。
- 时间片轮转调度算法(RR,Round-Robin) :每个进程被分配一个时间片,该进程允许运行的时间,当时间片结束让出CPU。
- 优先级调度算法(Priority):为每个进程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
- 多级反馈队列调度算法(MFQ,Multi-level Feedback Queue):它使用多个优先级不同的队列来组织进程,通常较高优先级的队列具有更短的时间片。基本思想是,当一个进程执行完其时间片时,它将被移到一个较低优先级的队列中,以便其他具有更高优先级的进程有机会运行。UNIX 操作系统采取的便是这种调度算法。
fork() 的实现细节
首先一个进程,包括代码、数据和分配给进程的资源。fork就是通过系统调用创建一个与原来进程几乎完全相同的进程,父子进程仅有pid的区别。
当父进程调用 fork() 时,操作系统会进行以下操作:
- 创建子进程:内核会为子进程分配一个新的进程控制块(Process Control Block,PCB),其中包括子进程的进程 ID、进程状态等信息。
- 复制页表:页表映射进程的虚拟地址空间到物理内存地址。fork() 时,内核不会复制父进程的所有内存,而是只复制父进程的页表,使子进程的页表指向相同的物理内存页。
- 设置内存页为只读:为了实现 Copy-On-Write 机制,内核会将父进程和子进程的内存页标记为只读。这样,任何对这些页的写操作都会触发一个页面保护异常(page fault)。
- 共享文件描述符:父进程和子进程共享打开的文件描述符,引用计数会增加。
写时复制(copy on write)的实现细节
初始状态:当父进程调用 fork() 时,子进程会共享父进程的所有内存页,这些内存页都会被标记为只读。
触发写保护:当父进程或子进程尝试写入某个内存页时,由于该页是只读的,会触发页面保护异常(page fault)。
处理写保护异常:操作系统捕获这个异常,并执行以下步骤:
- 分配一个新的物理内存页。
- 将原来只读内存页的内容复制到新的物理页中。
- 更新当前进程的页表,使该虚拟地址指向新的物理页。
- 将新的物理页设置为可写。
这样,只有试图写入的内存页会被复制,其他未被修改的内存页依然是共享的和只读的。
示例
假设有一个进程 P,其内存布局如下:
| 虚拟地址 | 物理地址 | 内容 |
|---|---|---|
| 0x1000 | 0xA000 | Data1 |
| 0x2000 | 0xB000 | Data2 |
调用 fork():
- 创建子进程 C,复制页表并共享内存页。
| 进程 | 虚拟地址 | 物理地址 | 内容 |
|---|---|---|---|
| P | 0x1000 | 0xA000 | Data1 |
| P | 0x2000 | 0xB000 | Data2 |
| C | 0x1000 | 0xA000 | Data1 |
| C | 0x2000 | 0xB000 | Data2 |
- 标记为只读:内核将这些内存页标记为只读。
- 子进程修改内存页:假设子进程 C 修改 0x1000 地址的内容,触发页面保护异常。
- 处理页面保护异常:
- 分配一个新的物理页 0xC000。
- 将 0xA000 页的内容复制到 0xC000。
- 更新子进程 C 的页表,使 0x1000 虚拟地址指向 0xC000。
- 将 0xC000 设置为可写。
| 进程 | 虚拟地址 | 物理地址 | 内容 |
|---|---|---|---|
| P | 0x1000 | 0xA000 | Data1 |
| P | 0x2000 | 0xB000 | Data2 |
| C | 0x1000 | 0xA000 | Data1(Modified) |
| C | 0x2000 | 0xB000 | Data2 |
优点:
- 节省内存:未修改的内存页依然共享,只有被修改的页才会被复制,节省了大量内存。
- 提高效率:避免在 fork() 调用时立即复制整个地址空间,提高了系统调用的性能。
什么是软中断和硬中断?
软中断:软中断是由软件或 CPU 指令生成的中断。例如系统调用(syscall)。硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断。
硬中断:硬中断是由硬件设备(比如网卡、硬盘)发出的中断信号,用于通知CPU 发生了某个事件,CPU 会停止当前执行的程序,转而执行与该中断相关的中断处理程序。
区别
1)引发对象:硬中断是由外设引发的,软中断是执行中断指令产生的。
2) 提供中断号:硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器。
3)耗时:硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为上半部。软中断处理硬中断未完成的工作,耗时比较长,是一种推后执行的机制,属于下半部。
什么是僵尸进程和孤儿进程?
在Unix/Linux系统中,子进程通常是通过fork()系统调用创建的。子进程和父进程的运行是相互独立的,它们各自拥有自己的PCB,即使父进程结束了,子进程仍然可以继续运行。
当子进程调用exit()系统调用结束时,内核会释放该进程的所有资源,但是该进程对应的PCB依然存在于系统中。这些信息只有在父进程调用wait()或waitpid()系统调用时才会被释放。
- 僵尸进程:子进程已经终止,但是其父进程仍在运行,且父进程没有调用wait()或waitpid()等系统调用来释放子进程占用的资源,导致子进程的PCB依然存在于系统中。这种情况下,子进程被称为“僵尸进程”。
- 孤儿进程:一个进程的父进程已经终止或者不存在,但是该进程仍在运行。这种情况就是孤儿进程。通常是由于父进程意外终止、未及时调用wait()或waitpid()等系统调用来回收子进程导致的。为了避免孤儿进程占用系统资源,操作系统会将孤儿进程的父进程设置为init进程(进程号为1),由init进程来回收孤儿进程的资源。
如何查看是否有僵尸进程?
Linux下可以使用Top命令查找,zombie 值表示僵尸进程的数量,为0则代表没有僵尸进程。
PCB 是什么?包含哪些信息?
PCB(Process Control Block) 即进程控制块,是操作系统中用来管理和跟踪进程的数据结构,每个进程都对应着一个独立的 PCB。
PCB 主要包含下面几部分的内容:
- 进程的描述信息,包括进程的名称、标识符等等;
- 进程的调度信息,包括进程状态(就绪、运行、阻塞等)、进程优先级(标识进程的重要程度)、进程阻塞原因等等;
- 进程对资源的需求情况,包括 CPU 时间、内存空间、I/O 设备等等。
- 进程打开的文件信息,包括文件描述符、文件类型、打开模式等等。
- 处理机状态:主要是由处理机的各种寄存器中的内容组成的。这些寄存器包括:
- ①通用寄存器,又称为用户可视寄存器,它们是用户程序可以访问的,用于暂存信息.
- ②指令计数器,其中存放了要访问的下一条指令的地址;
- ④用户栈指针,用于存放过程和系统调用参数及调用地址。栈指针指向该栈的栈顶。
线程的上下文切换需要切换什么东西?
线程的上下文切换需要切换以下关键内容,以保存当前线程的执行状态并恢复目标线程的状态,确保CPU能够无缝切换执行:
- 程序计数器(Program Counter, PC)
- 保存当前线程下一条待执行指令的地址,确保恢复时能继续执行。
- 寄存器状态
- 通用寄存器(如eax、ebx、ecx等):存储临时计算结果。
- 栈指针寄存器(SP):指向当前线程的栈顶位置。
- 基址指针寄存器(BP):用于函数调用栈帧的管理。
- 其他专用寄存器(如段寄存器、指令指针等)。
**状态寄存器:**保存CPU状态标志(如零标志、进位标志等),影响后续指令的条件执行。
**栈空间:**切换栈指针(SP),确保新线程使用自己的栈,保存函数调用链和局部变量。
性能影响
上下文切换的开销取决于保存和恢复的数据量。优化手段包括:
- 减少切换频率:通过协作式多任务或更高效的调度算法。
- 轻量级线程:如协程(Coroutine)或用户级线程,减少内核参与。
- 硬件支持:如快速上下文切换指令(如
futex)或寄存器窗口(SPARC架构)。
通过理解上下文切换的细节,可以更好地设计高并发系统,权衡性能与资源消耗。
三、I/O
I/O是什么?
I/O是指内存与外部设备之间的数据交互。因为CPU 与内存交互的速度远高于CPU和这些外部设备直接交互的速度,所以先把数据拷贝到内存中。
比如磁盘l/O指的是硬盘和内存之间的输入输出。
读取本地文件的时候,要将磁盘的数据拷贝到内存中,修改本地文件的时候,需要把修改后的数据拷贝到磁盘中。
网络I/O 指的是网卡与内存之间的输入输出。
当网络上的数据到来时,网卡需要将数据拷贝到内存中。当要发送数据给网络上的其他人时,需要将数据从内存拷贝到网卡里。
为什么网络I/O会阻塞?
- 数据传输速度不均衡:在网络通信中,发送方和接收方的数据传输速度可能不一致。当发送方发送数据快于接收方处理数据的速度时,接收方的缓冲区可能会满,导致发送方的I/0操作被阻塞,直到接收方处理完数据。
- 网络拥塞:当网络中的流量过大或网络传输带宽不足时,会导致网络拥塞。在拥塞的情况下,数据包的传输可能会延迟或丢失,导致发送方的I/O操作被阻塞。
- 阻塞式I/O操作:在一些传统的网络编程模型中,例如阻塞式I/O,当进行网络读取或写入操作时,程序会一直等待直到数据就绪或发送完成。
- 网络延迟(Latency):数据在网络中传输需要一定的时间,称为网络延迟。当数据在传输过程中受到延迟,程序可能会在等待数据返回时被阻塞。
网络I/O阻塞的解决方案
- 多线程处理:将网络I/O操作放在单独的线程中进行,可以避免主线程被阻塞,提高程序的并发性能。
- 非阻塞I/O(Non-blocking I/O):使用非阻塞I/O技术,程序可以在进行网络通信时立即返回,而不必等待数据的返回。通过轮询或事件驱动的方式,程序可以检查是否有数据可用,从而实现异步的网络通信。
- 使用缓存:可以减少对网络的频繁访问,提高了数据的读取和写入效率。
Java中有哪些I/O模型?
- 同步阻塞IO BIO
应用程序发起read调用后会一直阻塞,直到内核把数据拷贝到用户空间。优点就是简单,缺点很明显就是一个线程对应一个连接,一直被霸占着,一直需要阻塞着。
- 同步非阻塞I/O
在没数据的时候可以不再阻塞等着,而是直接返回错误,告知用户线程暂无准备就绪的数据。线程可以先去干干别的事情,然后再继续调用read看看有没有数据。这里要注意,从内核拷贝到用户空间这一步,用户线程还是会被阻塞的。
缺点在于:应用程序不断进行I/O系统调用轮询是十分消耗CPU资源的。
- I/O多路复用 NIO
可以只用一个线程查看多个连接是否有数据已准备就绪。我们可以往 selector注册需要被监听的连接,由selector来监控这些连接是否有数据已就绪,如果有则可以通知别的线程来read读取数据,这个 read 和之前的一样,还是会阻塞用户线程。
这样一来就可以用少量的线程去监控多条连接,减少了线程的数量,降低了内存的消耗。
- 异步I/O AIO
用户线程调用 aio_read,直接返回。之后内核等待数据准备完成,拷贝到内核,拷贝到用户空间。当内核操作完毕之后,再调用之前设置的回调,此时用户线程就拿着已经拷贝到用户空间的数据执行后续操作。
I/O多路复用的机制是什么?
NIO的核心是Selector选择器,一个selector可以注册多个channel,一个channel对应一个连接。当任意Channel发生读写事件时,就可以通过selector的select方法捕获到事件发生。这样我们就可以利用一个线程,死循环的调用 Selector.select(),就实现了利用一个线程管理多个连接,减少了线程数,减少了线程的上下文切换。
Select、Poll和Epoll之间有什么区别?
Select、Poll 和 Epoll 是用来实现I/O多路复用的机制,主要用于同时监视多个文件描述符的状态变化,包括可读、可写和异常事件。
- Select
Select 使用了一个 fd_set集合来保存需要监视的文件描述符,并提供了三个不同的集合来分别表示可读、可写和异常事件。Select 的主要缺点是效率较低,因为它采用轮询遍历的方式来检查每个文件描述符的状态变化,当文件描述符数量较大时,效率会明显下降。
- Poll
Poll 是对 Select的改进,以链表形式来保存需要监视的文件描述符,不受文件描述符数量的限制。但是select和poll都是使用线性结构来存储,都需要遍历轮询来检查状态变化。
- Epoll
Epoll 用了一个事件表来保存需要监视的文件描述符,并使用回调机制来通知应用程序发生的事件。可以避免轮询,只有在有事件发生时才会唤醒应用程序,因此效率更高。
Epoll中水平触发和边缘触发的区别?
epoll 是 Linux 系统中用于高效处理 I/O 事件的机制,它比传统的 select 或 poll 更适用于大量并发连接。epoll 提供了两种触发模式:水平触发(Level Triggered,LT)和边缘触发(Edge Triggered,ET),这两者的区别主要体现在事件的触发条件和触发频率上。
- 水平触发(Level Triggered, LT)
- 工作方式:在 LT 模式下,
epoll会一直通知应用程序,直到事件被处理完。例如,如果一个可读文件描述符没有被读取完,epoll会多次通知应用程序该文件描述符可读,直到应用程序将数据全部读取。 - 适用场景:通常是默认模式,适用于不希望丢失数据的场景。应用程序只需要不断读取即可,不必担心漏掉事件。
- 特点:
- 当
epoll发现有 I/O 可用时,如果没有及时处理,仍然会继续报告事件。 - 更容易理解和实现,因为事件不会“丢失”,只要条件成立,应用程序就会被提醒。
- 当
- 边缘触发(Edge Triggered, ET)
- 工作方式:在 ET 模式下,
epoll只在状态发生变化时才会通知应用程序。也就是说,只有在事件从“未就绪”变为“就绪”时才会触发通知。如果应用程序没有及时处理,事件就不会再被通知。例如,如果一个文件描述符变为可读状态,epoll只会触发一次通知,应用程序必须尽可能多地读取数据,直到没有更多数据可读,否则可能错过事件。 - 适用场景:通常用于性能要求更高的场景,能够减少不必要的系统调用,避免重复通知,提高效率。
- 特点:
- 只有在状态发生变化时才会触发一次通知。
- 需要特别小心处理 I/O,因为如果应用程序没有及时读取数据,可能会错过后续的事件。
- 通常需要非阻塞模式来避免被阻塞在单个操作上。
选择 LT 还是 ET?
- LT 模式比较安全,不容易出错,适合大多数情况。它会多次报告事件,确保应用程序处理完所有待处理的数据。
- ET 模式适合性能要求较高的应用,特别是在事件非常频繁、需要最大化并发处理的场景下。它可以减少系统调用和不必要的事件通知,但需要更加小心地设计事件处理逻辑,确保不丢失事件。
使用示例:
struct epoll_event ev;
ev.events = EPOLLIN; // 可读事件
ev.data.fd = fd;
// LT 模式是默认的,不需要特别指定
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, fd, &ev);
// ET 模式需要显式设置
ev.events = EPOLLIN | EPOLLET; // 设置 EPOLLET 启用边缘触发
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, fd, &ev);总结来说,LT 适用于简单易用的场景,ET 适用于对性能要求较高的场景。
死锁
什么是线程死锁?
线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
产生死锁的四个必要条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。
解决死锁的方法
解决死锁的方法可以从多个角度去分析,一般的情况下,有预防,避免,检测和解除四种。
- 预防 是采用某种策略,限制并发进程对资源的请求,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
- 避免则是系统在分配资源时,根据资源的使用情况提前做出预测,从而避免死锁的发生
- 检测是指系统设有专门的机构,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
- 解除 是与检测相配套的一种措施,用于将进程从死锁状态下解脱出来。
死锁的预防
死锁四大必要条件上面都已经列出来了,很显然,只要破坏四个必要条件中的任何一个就能够预防死锁的发生。
破坏第一个条件 互斥条件:使得资源是可以同时访问的,这是种简单的方法,磁盘就可以用这种方法管理,但是我们要知道,有很多资源 往往是不能同时访问的 ,所以这种做法在大多数的场合是行不通的。
破坏第三个条件 非抢占:也就是说可以采用 剥夺式调度算法,但剥夺式调度方法目前一般仅适用于 主存资源 和 处理器资源 的分配,并不适用于所有的资源,会导致 资源利用率下降。
所以一般比较实用的 预防死锁的方法,是通过考虑破坏第二个条件和第四个条件。
1、静态分配策略
静态分配策略可以破坏死锁产生的第二个条件(占有并等待)。所谓静态分配策略,就是指一个进程必须在执行前就申请到它所需要的全部资源,并且知道它所要的资源都得到满足之后才开始执行。进程要么占有所有的资源然后开始执行,要么不占有资源,不会出现占有一些资源等待一些资源的情况。
静态分配策略逻辑简单,实现也很容易,但这种策略 严重地降低了资源利用率,因为在每个进程所占有的资源中,有些资源是在比较靠后的执行时间里采用的,甚至有些资源是在额外的情况下才使用的,这样就可能造成一个进程占有了一些 几乎不用的资源而使其他需要该资源的进程产生等待 的情况。
2、层次分配策略
层次分配策略破坏了产生死锁的第四个条件(循环等待)。在层次分配策略下,所有的资源被分成了多个层次,一个进程得到某一次的一个资源后,它只能再申请较高一层的资源;当一个进程要释放某层的一个资源时,必须先释放所占用的较高层的资源,按这种策略,是不可能出现循环等待链的,因为那样的话,就出现了已经申请了较高层的资源,反而去申请了较低层的资源,不符合层次分配策略,证明略。
死锁的避免
死锁的避免相反,它的角度是允许系统中同时存在四个必要条件 ,进行合理的资源分配选择 ,避免死锁。
我们将系统的状态分为 安全状态 和 不安全状态 ,每当在为申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
那么如何保证系统保持在安全状态呢?通过算法,其中最具有代表性的 避免死锁算法 就是 Dijkstra 的银行家算法,银行家算法用一句话表达就是:当一个进程申请使用资源的时候,银行家算法 通过先 试探 分配给该进程资源,然后通过 安全性算法 判断分配后系统是否处于安全状态,若不安全则试探分配作废,让该进程继续等待,若能够进入到安全的状态,则就 真的分配资源给该进程。
银行家算法【available矩阵:可利用的资源量;Max:最大需求矩阵;Allocation:已分配的资源量;Need:仍需要的资源量】
死锁的避免(银行家算法)改善了 资源使用率低的问题 ,但是它要检测每个进程对各类资源的占用和申请情况和 安全性检查 ,需要花费较多的时间。
死锁的检测
解决死锁问题的另一条途径是 死锁检测和解除 (这里突然联想到了乐观锁和悲观锁,感觉死锁的检测和解除更加 乐观 ,分配资源时不去提前管会不会发生死锁了,等到真的死锁出现了再来解决。而 死锁的预防和避免 更加悲观锁,总是觉得死锁会出现,所以在分配资源的时候就很谨慎)。
这种方法对资源的分配不加以任何限制,也不采取死锁避免措施,但系统 定时地运行一个 “死锁检测” 的程序,判断系统内是否出现死锁,如果检测到系统发生了死锁,再采取措施去解除它。
进程-资源分配图
操作系统中的每一刻时刻的系统状态都可以用进程-资源分配图来表示,进程-资源分配图是描述进程和资源申请及分配关系的一种有向图,可用于检测系统是否处于死锁状态。
用一个方框表示每一个资源类,方框中的黑点表示该资源类中的各个资源,每个键进程用一个圆圈表示,用 有向边 来表示进程申请资源和资源被分配的情况。
图中 2-21 是进程-资源分配图的一个例子,其中共有三个资源类,每个进程的资源占有和申请情况已清楚地表示在图中。在这个例子中,由于存在 占有和等待资源的环路 ,导致一组进程永远处于等待资源的状态,发生了 死锁。
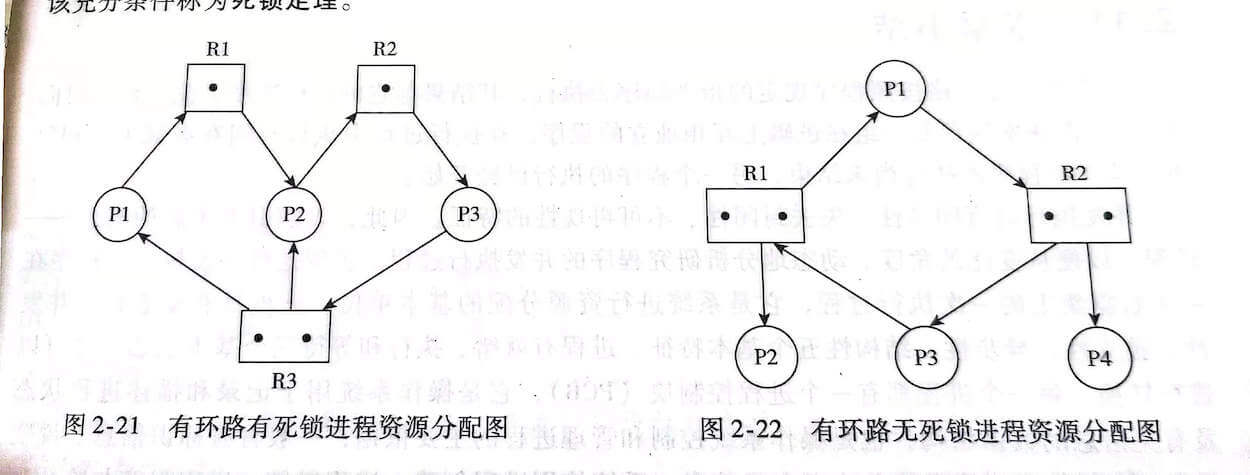
进程-资源分配图中存在环路并不一定是发生了死锁。因为循环等待资源仅仅是死锁发生的必要条件,而不是充分条件。图 2-22 便是一个有环路而无死锁的例子。虽然进程 P1 和进程 P3 分别占用了一个资源 R1 和一个资源 R2,并且因为等待另一个资源 R2 和另一个资源 R1 形成了环路,但进程 P2 和进程 P4 分别占有了一个资源 R1 和一个资源 R2,它们申请的资源得到了满足,在有限的时间里会归还资源,于是进程 P1 或 P3 都能获得另一个所需的资源,环路自动解除,系统也就不存在死锁状态了。
死锁检测步骤
知道了死锁检测的原理,我们可以利用下列步骤编写一个 死锁检测 程序,检测系统是否产生了死锁。
- 如果进程-资源分配图中无环路,则此时系统没有发生死锁
- 如果进程-资源分配图中有环路,且每个资源类仅有一个资源,则系统中已经发生了死锁。
- 如果进程-资源分配图中有环路,且涉及到的资源类有多个资源,此时系统未必会发生死锁。如果能在进程-资源分配图中找出一个 既不阻塞又非独立的进程 ,该进程能够在有限的时间内归还占有的资源,也就是把边给消除掉了,重复此过程,直到能在有限的时间内 消除所有的边 ,则不会发生死锁,否则会发生死锁。(消除边的过程类似于 拓扑排序)
死锁的解除
当死锁检测程序检测到存在死锁发生时,应设法让其解除,让系统从死锁状态中恢复过来,常用的解除死锁的方法有以下四种:
- 立即结束所有进程的执行,重新启动操作系统:这种方法简单,但以前所在的工作全部作废,损失很大。
- 撤销涉及死锁的所有进程,解除死锁后继续运行:这种方法能彻底打破死锁的循环等待条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
- 逐个撤销涉及死锁的进程,回收其资源直至死锁解除。
- 抢占资源:从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
如何利用指令检测死锁?
使用jmap、jstack等命令查看 JVM 线程栈和堆内存的情况。如果有死锁,jstack 的输出中通常会有 Found one Java-level deadlock:的字样,后面会跟着死锁相关的线程信息。另外,出现死锁可能会导致 CPU、内存等资源消耗过高。